Deep Learning ❤️ PyTorch

carefree0910
Individual DeveloperWe're happy to announce that carefree-learn released v0.2.0, which made it capable of solving not only tabular tasks, but also other general deep learning tasks!
Introduction
Deep Learning with PyTorch made easy 🚀!
Like many similar projects, carefree-learn can be treated as a high-level library to help with training neural networks in PyTorch. However, carefree-learn does more than that.
carefree-learnis highly customizable for developers. We have already wrapped (almost) every single functionality / process into a single module (a Python class), and they can be replaced or enhanced either directly from source codes or from local codes with the help of some pre-defined functions provided bycarefree-learn(see Register Mechanism).carefree-learnsupports easy-to-use saving and loading. By default, everything will be wrapped into a.zipfile, andonnxformat is natively supported!carefree-learnsupports Distributed Training.
Apart from these, carefree-learn also has quite a few specific advantages in each area:
Machine Learning 📈
carefree-learnprovides an end-to-end pipeline for tabular tasks, including AUTOMATICALLY deal with (this part is mainly handled bycarefree-data, though):- Detection of redundant feature columns which can be excluded (all SAME, all DIFFERENT, etc).
- Detection of feature columns types (whether a feature column is string column / numerical column / categorical column).
- Imputation of missing values.
- Encoding of string columns and categorical columns (Embedding or One Hot Encoding).
- Pre-processing of numerical columns (Normalize, Min Max, etc.).
- And much more...
carefree-learncan help you deal with almost ANY kind of tabular datasets, no matter how dirty and messy it is. It can be either trained directly with some numpy arrays, or trained indirectly with some files locate on your machine. This makescarefree-learnstand out from similar projects.
info
From the discriptions above, you might notice that carefree-learn is more of a minimal Automatic Machine Learning (AutoML) solution than a pure Machine Learning package.
tip
When we say ANY, it means that carefree-learn can even train on one single sample.
For example
This is especially useful when we need to do unittests or to verify whether our custom modules (e.g. custom pre-processes) are correctly integrated into carefree-learn.
For example
There is one more thing we'd like to mention: carefree-learn is Pandas-free. The reasons why we excluded Pandas are listed in carefree-data.
Computer Vision 🖼️
carefree-learnalso provides an end-to-end pipeline for computer vision tasks, and:Supports native
torchvisiondatasets.Currently only
mnistis supported, but will add more in the future (if needed) !Focuses on the
ImageFolderDatasetfor customization, which:- Automatically splits the dataset into train & valid.
- Supports generating labels in parallel, which is very useful when calculating labels is time consuming.
See IFD introduction for more details.
carefree-learnsupports various kinds ofCallbacks, which can be used for saving intermediate visualizations / results.- For instance,
carefree-learnimplements anArtifactCallback, which can dump artifacts to disk elaborately during training.
- For instance,
Examples
- Machine Learning 📈
- Computer Vision 🖼️
info
Please refer to Quick Start and Developer Guides for detailed information.
Migration Guide
From 0.1.x to v0.2.x, the design principle of carefree-learn changed in two aspects:
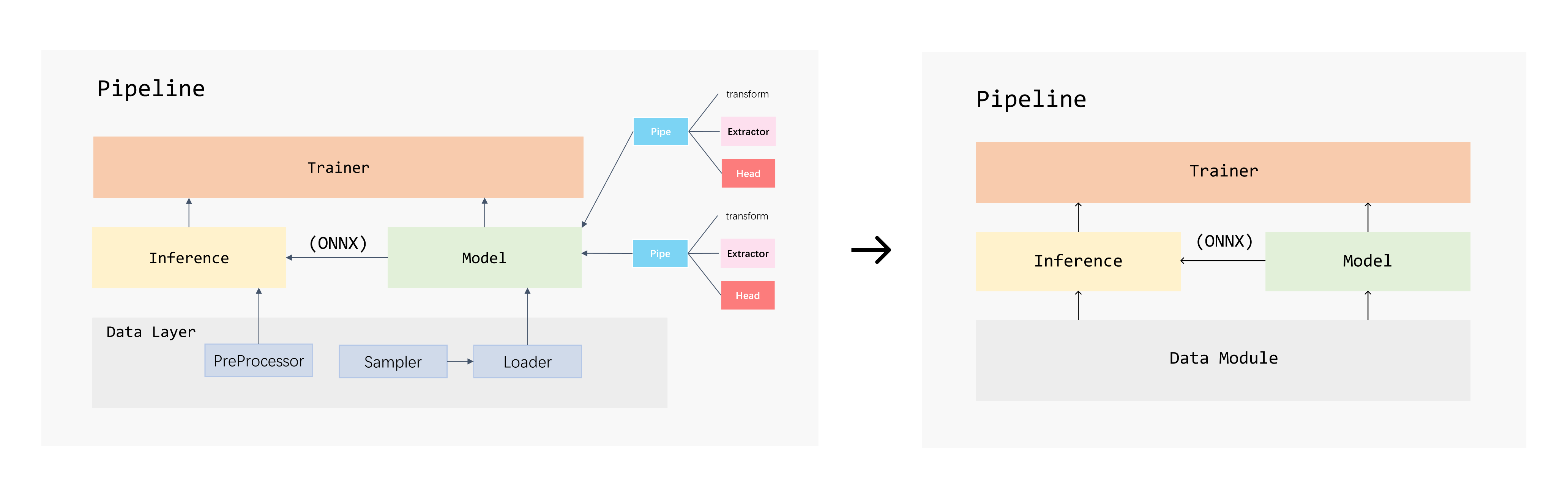 Framework change of carefree-learn (click to zoom in)
Framework change of carefree-learn (click to zoom in)
- The
DataLayerinv0.1.xhas changed to the more generalDataModuleinv0.2.x. - The
Modelinv0.1.x, which is constructed bypipes, has changed to generalModel.
These changes are made because we want to make carefree-learn compatible with general deep learning tasks (e.g. computer vision tasks).
Data Module
Internally, the Pipeline will train & predict on DataModule in v0.2.x, but carefree-learn also provided useful APIs to make user experiences as identical to v0.1.x as possible:
Train
- v0.1.x
- v0.2.x
Predict
- v0.1.x
- v0.2.x
Evaluate
- v0.1.x
- v0.2.x
Model
It's not very straight forward to migrate models from v0.1.x to v0.2.x, so if you require such migration, feel free to submit an issue and we will analyze the problems case by case!