Computer Vision 🖼️
tip
- For general introduction on how to use
carefree-learn, please refer to the General section. - For development guide, please refer to the Developer Guides section.
Introduction
In this section, we will introduce how to utilize carefree-learn to solve computer vision tasks.
What differs computer vision tasks to other deep learning tasks most is that, most of the dataset could be interpreted as 'Image Folder Dataset' (abbr: IFD). In this case, the source images (which will be the input of our models) will be stored in certain folder structure, and the labels (which will be the target of our models) can be represented by the hierarchy of each image file.
Therefore, carefree-learn introduces ImageFolderData as the unified data api for computer vision tasks. We will first introduce how different tasks could be represented as IFD, and will then introduce how to construct ImageFolderData in the next section.
Generation
Since generation tasks (usually) don't require labels, any image folder will be IFD itself.
Classification
There are many ways to construct classification tasks as IFD:
- Specify labels with the sub-folders' names.
- Specify labels with a
.csvfile, in which each row contains a file name and its corresponding label.
- Folder Name
- CSV File
labels.csv
Segmentation
The simplest way to construct segmentation tasks as IFD is to mimic the image folder structure and replace .png (image file) with .npy (mask file).
ImageFolderData
carefree-learn provides a convenient API (see prepare_image_folder_data) to construct ImageFolderData. But before we dive into details, it's necessary to know how carefree-learn organizes its IFD and how does it convert an IFD to the final ImageFolderData.
Design Principles
Since every task may have its own image folder structure, it will be very difficult to design a unified API to cover all the situations. carefree-learn therefore designs its own IFD pattern, and implements prepare_image_folder to convert other image folder structure to this pattern:
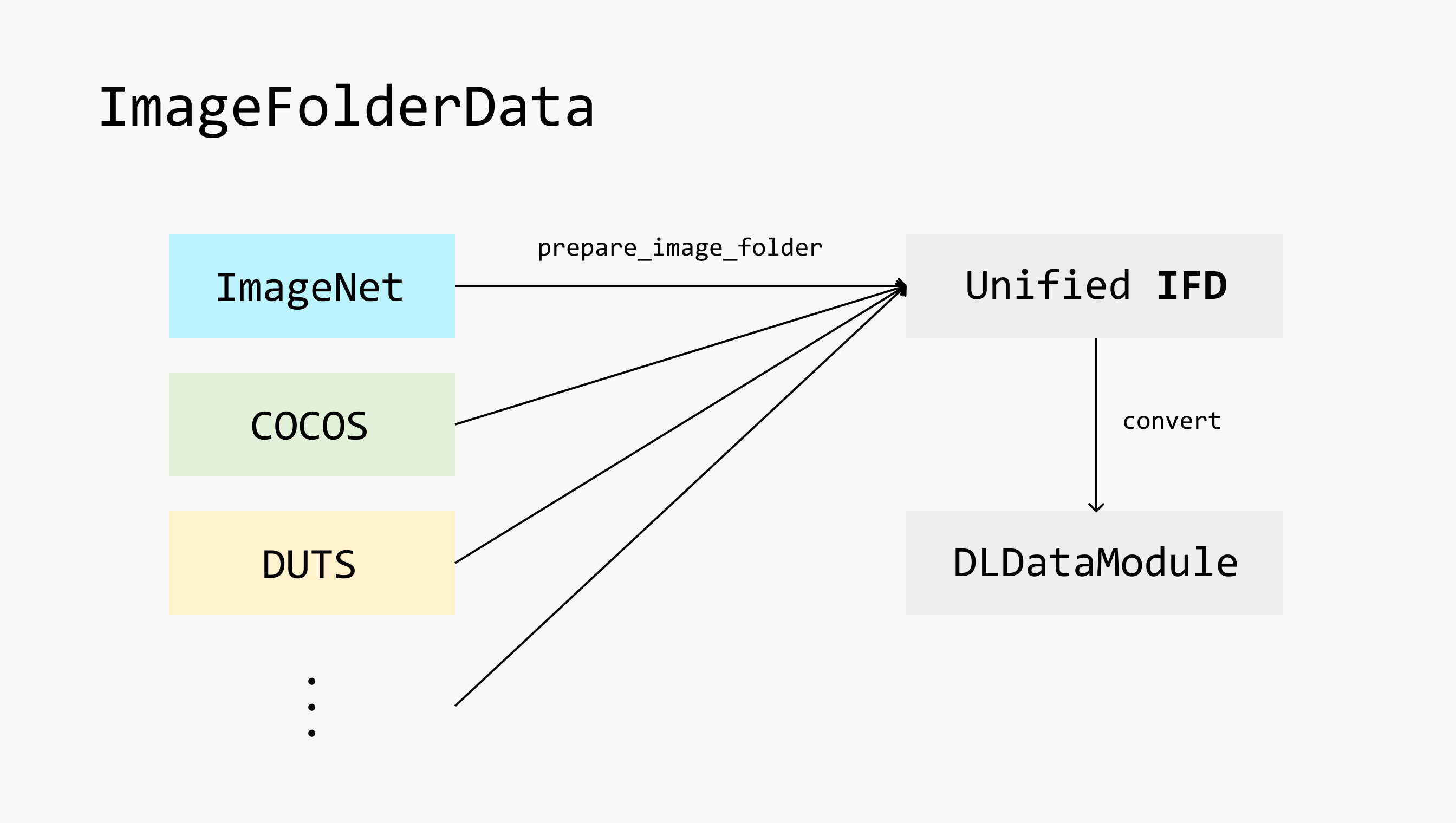
Unified IFD
In carefree-learn, we will expect the unified IFD to be as follows:
The
trainfolder represents all data used in training.- We will call it the 'train split' in the future.
The
validfolder represents all data used in valitation.- We will call it the 'valid split' in the future.
The
labels.jsonin each split represents the label information:The keys will be the absolute paths of the images, and the values will be the corresponding labels.
- If the labels are strings and end with
.npy, we will load the correspondingnp.ndarray. - Other wise, the labels should be integers / floats and will be kept as-is.
- If the labels are strings and end with
The
path_mapping.jsonin each split represents the path mapping:This means that the IFD in
carefree-learnshould be a copy of the original IFD, because we want to keep an individual version of each IFD.The
idx2labels.jsonrepresents the mapping from indices to original labels.- This is useful iff we are solving classification tasks and the original labels are strings.
The
labels2idx.jsonrepresents the mapping from original labels to indices.- This is useful iff we are solving classification tasks and the original labels are strings.
prepare_image_folder
src_folder- Path of the original IFD.
tgt_folder- Specify the path where we want to place our unified IFD.
to_index- Specify whether should we turn the original labels to indices.
- This is useful iff we are solving classification tasks and the original labels are strings.
prefix[default =None]- Specify the prefix of
src_folder. - Sometimes this is useful when we need to customize our own
_PreparationProtocol. - See
hierarchysection for more details.
- Specify the prefix of
preparation[default =DefaultPreparation()]- Specify the core logic of how to convert the original IFD to our unified IFD.
- See
_PreparationProtocolsection for more details.
force_rerun[default =False]- Specify whether should we force rerunning the whole prepare procedure.
- If
Falseand caches are available,prepare_image_folderwill be a no-op.
extensions[default ={".jpg", ".png"}]- Specify the extensions of our target image files.
make_labels_in_parallel[default =False]- Whether should we make labels in parallel.
- This will be very useful if making labels from the original IFD is time consuming.
num_jobs[default = 8]- Specify the number of jobs when we are:
- making labels in parallel.
- making a copy of the original IFD to construct the unified IFD.
- If
0, then no parallelism will be used.
- Specify the number of jobs when we are:
train_all_data[default =False]- Specify whether should we use all available data as train split.
- Basically this means we will use train set + validation set to train our model, while the validation set will remain the same.
valid_split[default =0.1]- Specify the number of samples in validation set.
- If
float, it will represent the portion. - If
int, it will represent the exact number. - Notice that the outcome of this argument will be effected by
max_num_valid.
max_num_valid[default =10000]- Specify the maximum number of samples in validation set.
lmdb_config[default =None]- Specify the configurations for
lmdb. - If not provided,
lmdbwill not be utilized.
- Specify the configurations for
use_tqdm[default =True]- Specify whether should we use
tqdmprogress bar to monitor the preparation progress.
- Specify whether should we use
_PreparationProtocol
In order to provide a convenient API to implement the core logic of converting the original IFD to our unified IFD, carefree-learn implemented _PreparationProtocol and exposed some methods for users to override. By default, carefree-learn will use DefaultPreparation which can handle some general cases:
For specific cases, we can override one or more methods as shown above to customize the behaviours. We will first introduce these methods in details, and then will provide some examples on how to use it.
extra_labels- This property specifies the extra labels required by current task.
- Usually we can safely leave it as
None, unless we need to use multiple labels in one sample. - See
extra_labelsexample for more details.
filter- This method is used to filter out which images do we want to copy from the original IFD.
- Will be useful when:
- the original IFD contains some 'dirty' images (truncated, broken, etc.).
- we only want to play with a specific portion of the original IFD.
- See
hierarchysection for detailed definition of thehierarchyargument. - See
filterexample for more details.
get_label- This method is used to define the label of each input image.
- If returning string and ends with
.npy, it should represent annp.ndarraypath, which will be loaded when constructing the input sample. - If returning other strings, they will be converted to indices based on
labels2idx.json. - If returning integer / float, they will be kept as-is.
- See
hierarchysection for detailed definition of thehierarchyargument. - See
get_labelexample for more details.
get_extra_label- This method is used to define the extra label(s) of each input image.
- If returning string and ends with
.npy, it should represent annp.ndarraypath, which will be loaded when constructing the input sample. - If returning other strings, they will be converted to indices based on
labels2idx.json. - If returning integer / float, they will be kept as-is.
- See
hierarchysection for detailed definition of thehierarchyargument. - See
extra_labelsexample for more details.
copy- This method is used to copy images from the original IFD to our unified IFD.
- Will be useful if we want to pre-check the quality of each image, because if this method raises an error, the corresponding image will be filtered out from the unified IFD.
- See
copyexample for more details.
hierarchy
A hierarchy in _PreparationProtocol is a list of string, representing the file hierarchy. For example, if the original IFD looks as follows:
Then the hierarchy of data/dog/0.png will be:
However, sometimes the original IFD may locate on shared spaces, which means it will be difficult to get the relative path:
In this case, we can specify the prefix argument in prepare_image_folder:
Here, src_folder is set to "data" and prefix is set to "/home/shared", which means:
- We will use
"/home/shared/data"as the finalsrc_folder. - The
hierarchywill strip out"/home/shared", which means thehierarchyof/home/shared/data/dog/0.pngwill still be:
This mechanism can guarantee that the same _PreparationProtocol can be used across different environment (with only prefix modified), as long as the original IFD has not changed.
Examples
info
This section focuses on how to construct a unified IFD. For how to construct a DLDataModule from a unifed IFD, please refer to the ImageFolderData section.
extra_labels example
Suppose the original IFD looks as follows:
labels.csv
Then the _PreparationProtocol could be defined as:
After executing:
We will get the following unified IFD:
The highlighted lines show the main differences when extra_labels mechanism is applied.
filter example
Suppose the original IFD looks as follows:
And we don't want those image files that end with dummy to be in our unified IFD. Then the _PreparationProtocol could be defined as:
get_label example
Suppose the original IFD looks as follows:
And the images are RGBA images, whose alpha channel will be our segmentation mask (label). Then the _PreparationProtocol could be defined as:
After executing:
We will get the following unified IFD:
- A
labelsfolder will be created to store the extracted alpha mask. - Neither
idx2labels.jsonnorlabels2idx.jsonwill be generated, because all labels are.npyfiles.
copy example
The most common use case of overriding copy method is to pre-verify the original images:
ImageFolderData
info
In this section, we will use loader to represent DataLoader from PyTorch.
After the unified IFD is ready, constructing ImageFolderData will be fairly straightforward:
folder- Specify the path to the unified IFD.
batch_size- Specify the number of samples in each batch.
num_workers[default =0]- Argument used in
loader.
- Argument used in
shuffle[default =True]- Argument used in
loader.
- Argument used in
drop_train_last[default =True]- Whether should we apply
drop_lastinloaderin training set. - Notice that for validation set,
drop_lastwill always beFalse.
- Whether should we apply
prefetch_device[default =None]- If not specified, the
prefetchmechanism will not be applied. - If specified,
carefree-learnwill 'prefetch' each batch to the corresponding device.
- If not specified, the
pin_memory_device[default =None]- If not specified, the
pin_memorymechanism will not be applied. - If specified,
carefree-learnwill usepin_memoryinloaderto the corresponding device.
- If not specified, the
extra_label_names[default =None]- Should be the value of the
extra_labelsproperty in_PreparationProtocol.
- Should be the value of the
transform[default =None]- Specify the transform we would like to apply to the original batch.
- See Transforms section for more details.
transform_config[default =None]- Specify the configuration of
transform.
- Specify the configuration of
test_shuffle[default =None]- Argument used in
loaderin test set. - If not specified, it will be the same as
shuffle.
- Argument used in
test_transform[default =None]- Specify the transform we would like to apply to the original batch.
- If not specified, it will be the same as
transform. - See Transforms section for more details.
test_transform_config[default =None]- Specify the configuration of
test_transform. - If not specified, it will be the same as
transform_config.
- Specify the configuration of
lmdb_config[default =None]- Specify the configurations for
lmdb. - If not provided,
lmdbwill not be utilized. - Should be the same as
lmdb_configused inprepare_image_folder.
- Specify the configurations for
prepare_image_folder_data
To make things easier, carefree-learn provides prepare_image_folder_data API to directly construct a ImageFolderData from the original IFD:
Transforms
Source code: transforms
Data augmentation plays an important role in Computer Vision. In carefree-learn, we provided three kinds of transforms to apply data augmentations:
- PyTorch native transforms: pt.py.
- albumentations transforms: A.py.
- Some commonly used transform pipelines: interface.py.
These transforms are managed under the register mechanism, so we can access them by their names:
Where to_tensor transform is defined as follows:
tip
- For supported transforms, please refer to the source code.
- For customizing transforms, please refer to the Customize Transforms section.